Ever wondered why your server crashes or your app slows down? A powerful system monitor might be the silent hero you’re missing. Let’s dive into how real-time insights can transform your IT operations.




What Is a System Monitor and Why It Matters

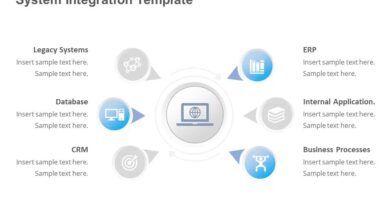
A system monitor is more than just a dashboard of blinking lights and fluctuating graphs. At its core, it’s a software solution designed to track, analyze, and report on the health and performance of computer systems—be it a single desktop, a network of servers, or cloud-based infrastructure. In today’s hyper-connected digital world, where downtime can cost thousands per minute, having a reliable system monitor isn’t optional—it’s essential.
Core Functions of a System Monitor
The primary role of any system monitor is to provide continuous oversight of critical system metrics. This includes tracking CPU usage, memory consumption, disk I/O, network bandwidth, and process activity. By collecting this data in real time, a system monitor enables administrators to detect anomalies before they escalate into full-blown outages.
- Real-time performance tracking
- Automated alerting for threshold breaches
- Historical data logging for trend analysis
For example, if a database server suddenly spikes to 95% CPU usage, a well-configured system monitor will trigger an alert, allowing the team to investigate whether it’s due to a rogue query, a DDoS attack, or scheduled batch processing.
Types of System Monitoring
Not all monitoring is created equal. Depending on the environment and objectives, organizations deploy different types of system monitoring:
- Infrastructure Monitoring: Focuses on hardware and OS-level metrics like temperature, disk space, and uptime.
- Application Performance Monitoring (APM): Tracks software behavior, response times, and transaction flows.
- Network Monitoring: Observes traffic patterns, latency, packet loss, and firewall status.
Each type serves a unique purpose but often overlaps within a comprehensive monitoring strategy. Tools like Zabbix and Nagios offer modular platforms that support all three.
“Monitoring is not about collecting data—it’s about making data actionable.” — DevOps Engineer, Google Cloud
Top 7 System Monitor Tools in 2024
Choosing the right system monitor can make or break your IT operations. With dozens of tools available, each boasting unique features, it’s crucial to evaluate them based on scalability, ease of use, integration capabilities, and cost. Below are seven of the most powerful and widely adopted system monitor solutions in 2024.
1. Zabbix: Open-Source Powerhouse
Zabbix stands out as one of the most robust open-source system monitor platforms. It supports both agent-based and agentless monitoring across Linux, Windows, and Unix systems. Its strength lies in its flexibility—users can customize triggers, create complex dependency maps, and generate detailed reports.
- Supports over 1,000 metrics out of the box
- Highly scalable for enterprise environments
- Active community and extensive documentation
Zabbix excels in environments requiring deep customization and long-term data retention. For more details, visit the official site at zabbix.com.
2. Nagios XI: The Veteran with Modern Flair
Nagios has been a staple in system monitoring since 1999. Nagios XI, its commercial version, enhances the original with a modern web interface, advanced dashboards, and seamless plugin integration. It’s particularly popular among mid-sized businesses with mixed IT environments.
- Extensive plugin ecosystem (over 5,000 available)
- Proactive alerting via email, SMS, and Slack
- Built-in capacity planning tools
While Nagios Core is free, Nagios XI requires a subscription, making it ideal for teams needing enterprise-grade support. Learn more at nagios.org.
3. Datadog: Cloud-Native Champion
Datadog has emerged as a leader in cloud-based system monitoring. Designed for dynamic environments running on AWS, Azure, or GCP, it offers real-time visibility into servers, containers, and serverless functions. Its AI-powered anomaly detection sets it apart from traditional tools.
- Automatic discovery of cloud resources
- Integrated APM and log management
- Powerful collaboration features via shared dashboards
Datadog’s pricing model is usage-based, which can become expensive at scale, but its ease of deployment and rich feature set justify the cost for many DevOps teams.
4. Prometheus: The Kubernetes Native Choice
Prometheus is the go-to system monitor for Kubernetes and microservices architectures. Originally developed at SoundCloud, it uses a pull-based model to collect time-series data from instrumented jobs. Its query language, PromQL, is powerful and expressive.
- Highly efficient storage engine optimized for metrics
- Excellent integration with Grafana for visualization
- Strong support for service discovery in containerized environments
Prometheus shines in ephemeral environments where traditional monitoring tools struggle. It’s part of the Cloud Native Computing Foundation (CNCF) and is widely used in CI/CD pipelines. Explore it at prometheus.io.
5. SolarWinds Server & Application Monitor (SAM)
SolarWinds SAM is a comprehensive solution for monitoring both physical and virtual servers along with business-critical applications. It provides deep application stack visibility—from the database layer to the user interface.
- Pre-built templates for SAP, Oracle, Microsoft SQL Server
- Automated root cause analysis
- Customizable alerts and reports
While praised for its ease of use, SolarWinds has faced scrutiny after the 2020 supply chain attack. However, the company has since overhauled its security practices, and SAM remains a top contender for enterprise monitoring.
6. PRTG Network Monitor: All-in-One Suite
Paessler’s PRTG is a Windows-based system monitor that combines infrastructure, network, and application monitoring in a single platform. It uses sensors to gather data—each sensor monitors one aspect (e.g., CPU load, HTTP response time).
- Over 200 sensor types available
- Intuitive drag-and-drop interface
- Free version supports up to 100 sensors
PRTG is ideal for small to medium businesses looking for an all-in-one solution without the complexity of open-source tools. More info at paessler.com/prtg.
7. New Relic: Full-Stack Observability
New Relic offers a full-stack observability platform that goes beyond basic system monitoring. It integrates metrics, events, logs, and traces (MELT) into a unified interface, enabling teams to understand not just *what* is happening, but *why*.
- Real-user monitoring (RUM) for web applications
- AI-driven insights with ‘Applied Intelligence’
- OpenTelemetry support for vendor-neutral data collection
New Relic’s free tier is generous, making it accessible for startups and developers. For enterprise users, it scales seamlessly across global deployments.
Key Metrics Tracked by a System Monitor
A good system monitor doesn’t just collect data—it collects the *right* data. Understanding which metrics matter most can help you optimize performance, prevent failures, and justify infrastructure investments.
CPU Usage and Load Average
CPU utilization is one of the most fundamental metrics. A sustained usage above 80% typically indicates a bottleneck. However, it’s equally important to monitor the load average—the number of processes waiting for CPU time over 1, 5, and 15 minutes.
- High CPU usage with low load: Likely a single-threaded application maxing out one core
- High load with moderate CPU: Could indicate I/O wait or thread contention
- Consistently high values: May require vertical or horizontal scaling
Tools like top, htop, and sar provide granular CPU insights, while system monitor platforms visualize these trends over time.
Memory Utilization and Swap Activity
Memory pressure is a silent killer of system performance. When RAM is exhausted, the OS starts using swap space on disk, which is orders of magnitude slower. A system monitor should track:
- Total, used, and free memory
- Swap in/out rates
- Page faults per second
Persistent swapping is a red flag. It often leads to thrashing—where the system spends more time moving data between RAM and disk than executing tasks. Monitoring tools can alert when swap usage exceeds a safe threshold (e.g., 10%).
Disk I/O and Latency
Disk performance is critical for databases, file servers, and virtual machines. Key indicators include:
- Read/write throughput (MB/s)
- IOPS (Input/Output Operations Per Second)
- Average response time (latency)
High latency (>20ms for SSDs) suggests contention or hardware degradation. A system monitor with predictive analytics can forecast disk failure by tracking SMART attributes or sudden performance drops.
“You can’t manage what you can’t measure.” — W. Edwards Deming
How to Choose the Right System Monitor for Your Needs
Selecting a system monitor isn’t a one-size-fits-all decision. The best choice depends on your infrastructure, team expertise, budget, and long-term goals. Here’s a structured approach to guide your evaluation.
Assess Your Environment and Scale
Start by mapping your IT landscape. Are you running on-premises servers, public cloud, hybrid, or containerized workloads? A small business with five servers might thrive with PRTG or Zabbix, while a global SaaS company may need Datadog or New Relic.
- Number of nodes to monitor
- Geographic distribution
- Rate of change (e.g., auto-scaling groups)
Scalability is crucial. Some tools require additional licenses per node, while others charge based on data volume. Factor in future growth to avoid costly migrations later.
Evaluate Integration and Automation Capabilities
Modern DevOps workflows rely on automation. Your system monitor should integrate with tools like:
- CI/CD pipelines (Jenkins, GitHub Actions)
- Incident management (PagerDuty, Opsgenie)
- Configuration management (Ansible, Puppet)
API access is non-negotiable. It allows you to automate alert routing, generate compliance reports, and embed monitoring data into internal dashboards.
Consider Total Cost of Ownership (TCO)
Cost extends beyond licensing. Consider:
- Hardware requirements (for on-prem tools)
- Staff training and maintenance time
- Opportunity cost of downtime due to poor monitoring
Open-source tools like Zabbix and Prometheus have zero license fees but may require more in-house expertise. Commercial tools offer faster setup and support but at a recurring cost.
Setting Up Your First System Monitor: A Step-by-Step Guide
Ready to deploy your first system monitor? Follow this practical guide to get up and running efficiently.
Step 1: Define Monitoring Objectives
Before installing any software, clarify what you want to achieve. Common goals include:
- Reducing mean time to detect (MTTD) incidents
- Improving system uptime and reliability
- Optimizing resource utilization
Document key performance indicators (KPIs) such as uptime percentage, alert response time, and incident resolution rate.
Step 2: Select and Install the Tool
Based on your assessment, choose a tool. For this example, let’s use Zabbix:
- Download Zabbix server, frontend, and agent packages
- Install on a dedicated Linux server (Ubuntu/CentOS)
- Configure the database (MySQL/PostgreSQL)
- Launch the web installer and complete setup
Detailed instructions are available at Zabbix Documentation.
Step 3: Configure Hosts and Templates
Add the systems you want to monitor:
- In the Zabbix web interface, go to ‘Configuration > Hosts’
- Create a new host, specifying IP and DNS name
- Link a template (e.g., ‘Template OS Linux’)
- Install the Zabbix agent on the target machine
Templates automate the creation of items (metrics), triggers (alerts), and graphs, saving significant configuration time.
Step 4: Set Up Alerts and Notifications
Define when and how you’ll be notified:
- Create a media type (e.g., email, Slack webhook)
- Assign it to user accounts
- Configure trigger conditions (e.g., CPU > 90% for 5 minutes)
- Test alert delivery
Effective alerting avoids noise—ensure alerts are actionable and prioritized.
Advanced Features of Modern System Monitor Platforms
Today’s top-tier system monitor tools go far beyond basic metric collection. They offer intelligent features that transform raw data into operational intelligence.
AI-Powered Anomaly Detection
Traditional threshold-based alerts often result in false positives or missed issues. AI-driven monitoring uses machine learning to establish baselines and detect deviations.
- Learns normal behavior over time (e.g., weekday vs. weekend traffic)
- Identifies subtle trends that humans might overlook
- Reduces alert fatigue by filtering out noise
Datadog’s ‘Anomaly Detection’ and New Relic’s ‘Applied Intelligence’ are prime examples of this technology in action.
Automated Root Cause Analysis
When an incident occurs, time is critical. Advanced system monitors can correlate events across layers to pinpoint the source.
- Traces a slow web request back to a specific database query
- Links a server crash to a recent configuration change
- Visualizes dependencies between services
This capability drastically reduces mean time to resolution (MTTR), a key metric for IT teams.
Custom Dashboards and Reporting
One-size-fits-all dashboards don’t work for everyone. Modern tools allow users to build role-specific views:
- Executive summary: Uptime, SLA compliance, cost trends
- Operations view: Real-time server health, alert status
- Developer view: API latency, error rates, deployment impact
Grafana, often paired with Prometheus, is a leader in customizable visualization.
Common Pitfalls in System Monitoring and How to Avoid Them
Even with the best tools, poor practices can undermine your monitoring strategy. Awareness of common mistakes is the first step to avoiding them.
Alert Fatigue: Too Many Notifications
When alerts become background noise, critical issues get ignored. This is known as alert fatigue.
- Solution: Implement alert deduplication and escalation policies
- Use severity levels (Critical, Warning, Info)
- Suppress non-actionable alerts during maintenance windows
Regularly review and tune your alerting rules to maintain relevance.
Monitoring Without Context
Knowing that CPU is at 100% is useless without understanding *why*. Context includes:
- Recent deployments or configuration changes
- Associated application logs
- User impact (e.g., transaction failure rate)
Integrate your system monitor with logging and tracing tools to gain full context.
Ignoring Historical Trends
Monitoring isn’t just about the present—it’s about predicting the future. Failing to analyze historical data leads to reactive rather than proactive management.
- Solution: Enable long-term data retention
- Use forecasting models to predict resource exhaustion
- Schedule regular performance reviews
For instance, if disk usage grows at 5% per month, you can plan upgrades months in advance.
“The goal of monitoring is not to record the past, but to prevent future failures.” — Site Reliability Engineer, Netflix
What is a system monitor?
A system monitor is a software tool that tracks the performance and availability of computer systems, networks, and applications. It collects metrics like CPU usage, memory, disk I/O, and network activity to ensure optimal operation and rapid issue detection.
What are the best open-source system monitor tools?
Zabbix and Prometheus are among the most powerful open-source system monitor solutions. Zabbix offers comprehensive infrastructure monitoring, while Prometheus excels in cloud-native and containerized environments.
How does a system monitor reduce downtime?
By providing real-time alerts and historical trend analysis, a system monitor enables teams to detect and resolve issues before they cause outages, significantly reducing mean time to detection (MTTD) and mean time to resolution (MTTR).
Can a system monitor work in the cloud?
Yes, modern system monitor tools like Datadog, New Relic, and Prometheus are designed to operate seamlessly in cloud environments, supporting auto-discovery, dynamic scaling, and multi-region monitoring.
Is system monitoring only for large enterprises?
No, system monitoring benefits organizations of all sizes. Small businesses can use free or low-cost tools like PRTG (free up to 100 sensors) or Zabbix to improve reliability and performance.
Choosing the right system monitor is a strategic decision that impacts reliability, efficiency, and user satisfaction. From open-source stalwarts like Zabbix to AI-powered platforms like Datadog, the options are vast. The key is aligning the tool with your environment, goals, and team capabilities. By tracking critical metrics, setting up intelligent alerts, and avoiding common pitfalls, you can transform your IT operations from reactive to proactive. In an era where digital performance equals business success, a robust system monitor isn’t just a tool—it’s a competitive advantage.
Further Reading: